Efficient Search Engine Measurements
1 Introduction
Background. In this paper we focus on
methods for external evaluation of search engines. These methods
interact only with the public interfaces of search engines and do
not rely on privileged access to internal search engine data or
on specific knowledge of how the search engines work. External
evaluation provides the means for objective benchmarking of
search engines. Such benchmarks can be used by search engine
users and clients to gauge the quality of the service they get
and by researchers to compare search engines. Even search engines
themselves may benefit from external benchmarks, as they can help
them reveal their strengths and weaknesses relative to their
competitors.
Our study concentrates on measurement of global quality metrics of search engines, like corpus size, index freshness, and density of spam or duplicate pages in the corpus. Such metrics are relevance neutral, and therefore no human judgment is required for computing them. Still, as external access to search engine data is highly restricted, designing automatic methods for measuring these quality metrics is very challenging. Our objective is to design measurement algorithms that are both accurate and efficient. Efficiency is particularly important for two reasons. First, efficient algorithms can be executed even by parties whose resources are limited, like researchers. Second, as search engines are highly dynamic, efficient algorithms are necessary for capturing instantaneous snapshots of the search engines.
Problem statement. Let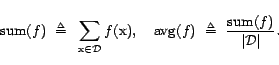
(In fact, we address sums and averages w.r.t. arbitrary measures. See more details in Section 2.) Almost all the global quality metrics we are aware of can be expressed as sum or average metrics. For example, the corpus size,
A search engine estimator for
![]() (resp.,
(resp.,
![]() ) is a
probabilistic procedure, which submits queries to the search
engine, fetches pages from the web, computes the target function
) is a
probabilistic procedure, which submits queries to the search
engine, fetches pages from the web, computes the target function
![]() on documents of its
choice, and eventually outputs an estimate of
on documents of its
choice, and eventually outputs an estimate of
![]() (resp.,
(resp.,
![]() ). The
quality of an estimator is measured in terms of its bias
and its variance. The efficiency of an estimator is
measured in terms of the number of queries it submits to the
search engine, the number of web pages it fetches, and the number
of documents on which it computes the target function
). The
quality of an estimator is measured in terms of its bias
and its variance. The efficiency of an estimator is
measured in terms of the number of queries it submits to the
search engine, the number of web pages it fetches, and the number
of documents on which it computes the target function ![]() .
.
An alternative to brute-force computation is sampling. One samples random pages from the corpus and uses them to estimate the quality metrics. If the samples are unbiased, then a small number of them is sufficient to obtain accurate estimations. The main challenge is to design algorithms that can efficiently generate unbiased samples from the corpus using queries to the public interface. Bharat and Broder [4] were the first to propose such an algorithm. The samples produced by their algorithm, however, suffered from severe bias towards long, content-rich, documents. In our previous paper [2], we were able to correct this bias by proposing a technique for simulating unbiased sampling by biased sampling. To this end, we applied several stochastic simulation methods, like rejection sampling [24] and the Metropolis-Hastings algorithm [22,13]. Stochastic simulation, however, incurs significant overhead: in order to generate each unbiased sample, numerous biased samples are used, and this translates into elevated query and fetch costs. For instance, our most efficient sampler needed about 2,000 queries to generate each uniform sample.
In an attempt to address this lack of efficiency, we also experimented [2] with importance sampling estimation. Importance sampling [21,16] enables estimation of sums and averages directly from the biased samples, without first generating unbiased samples. This technique can significantly reduce the stochastic simulation overhead. Nevertheless, our estimators in [2] used stochastic simulation twice (once to select random queries and once to select random documents), and we were able to use importance sampling to eliminate only the latter of the two. Furthermore, our importance sampling estimator was still wasteful, as it used only a single result of each submitted query and discarded all the rest.
Broder et al. [6] have recently made remarkable progress by proposing a new estimator for search engine corpus size. Their estimator (implicitly) employs importance sampling and does not resort to stochastic simulation at all. Moreover, the estimator somehow makes use of all query results in the estimation and is thus less wasteful than the estimators in [2]. Broder et al. claimed their method can be generalized to estimate other metrics, but have not provided any details.
The degree mismatch problem. A prerequisite for applying importance sampling is the ability to compute for each biased sample an importance weight. The importance weights are used to balance the contributions of the different biased samples to the final estimator.In the estimators of [2,6], computing the
importance weight of a sample document translates into
calculation of the document's ``degree''. Given a large pool of
queries (e.g., ``phrase queries of length 5'', or ``8-digit
string queries''), the degree of a document w.r.t. the
pool is the number of queries from the pool to whose results
![]() belongs. As the
estimators of [2,6] choose their sample
documents from the results of random queries drawn from a query
pool, these samples are biased towards high degree documents.
Document degrees, therefore, constitute the primary factor in
determining the importance weights of sample documents.
belongs. As the
estimators of [2,6] choose their sample
documents from the results of random queries drawn from a query
pool, these samples are biased towards high degree documents.
Document degrees, therefore, constitute the primary factor in
determining the importance weights of sample documents.
As importance weights (and hence degrees) are computed for
every sample document, degree computation should be extremely
efficient. Ideally, it should be done based on the content of
![]() alone and without
submitting queries to the search engine. The above estimators do
this by extracting all the terms/phrases from
alone and without
submitting queries to the search engine. The above estimators do
this by extracting all the terms/phrases from ![]() and counting how
many of them belong to the pool. The resulting number is the
document's predicted degree and is used as an
approximation of the real degree.
and counting how
many of them belong to the pool. The resulting number is the
document's predicted degree and is used as an
approximation of the real degree.
In practice, the predicted degree may be quite different from the actual degree, since we do not exactly know how the search engine parses documents or how it selects the terms by which to index the document. Moreover, we do not know a priori which of the queries that the document matches overflow; the document may fail to belong to the result sets of such queries if it is ranked too low. These factors give rise to a degree mismatch--a gap between the predicted degree and the actual degree. The degree mismatch implies that the importance weights used by the estimators are not accurate, and this can significantly affect the quality of the produced estimates.
In [2], we proved that if the density of overflowing queries among all the queries that a document matches has low variance, then the bias incurred by degree mismatch is small. Broder et al. [6] have not analyzed the effect of degree mismatch on the quality of their estimations.
Several heuristic methods have been used by [2,6] to overcome the degree mismatch problem. In order to reduce the effect of overflowing queries, a pool of queries that are unlikely to overflow was chosen ([2] used a pool of phrases of length 5, while [6] used a pool of 8-digit strings). However, pools that have low density of overflowing queries are also more likely to have poor coverage, creating another bias. [6] remove overflowing queries from the pool by eliminating terms that occur frequently in a training corpus. However, this heuristic can have many false positives or false negatives, depending on the choice of the frequency threshold.
Our contributions. In this paper we show how to overcome the degree mismatch problem. We present two search engine estimators that remain nearly unbiased and very efficient, even in the presence of highly mismatching degrees.Our first contribution is a rigorous analysis of an ``approximate importance sampling'' procedure. We prove that using importance sampling with approximate weights rather than the real weights incurs both a multiplicative bias and an additive bias. The analysis immediately implies that the estimator of Broder et al. [6] suffers from significant bias in the presence of degree mismatch.
Our second contribution is the design of two new importance sampling estimators. Our estimators use approximate weights, but are able to eliminate the more significant multiplicative bias, leading to nearly unbiased estimates. These estimators can be viewed as generalizations of ``ratio importance sampling'' (cf. [20]) and importance sampling with approximate trial weights [2]. The first estimator, the Accurate Estimator (AccEst), uses few search engine queries to probabilistically calculate exact document degrees, and is thereby able to achieve essentially unbiased estimations. The second estimator, the Efficient Estimator (EffEst), predicts document degrees from the contents of documents alone, without submitting queries to the search engine, similarly to [2,6]. To eliminate the multiplicative bias factor incurred by degree mismatch, EffEst estimates this factor by invoking AccEst. Nevertheless, as the bias factor is independent of the target function being measured, this costly computation can be done only once in a pre-processing step, and then be reused in multiple invocations of EffEst. Hence, the amortized cost of EffEst is much lower than that of AccEst. The estimations produced by EffEst may be slightly less accurate than those of AccEst, because the additive bias cannot be always eliminated.
We note that our estimators are applicable to both the sum metric and the average metric w.r.t. any target function. This in contrast to the estimators in [2], which are efficiently applicable only to average metrics, and the estimator in [6], which is applicable only to sum metrics.
Our last contribution builds on the observation that the estimator of Broder et al. implicitly applies Rao Blackwellization [7], which is a well-known statistical tool for reducing estimation variance. This technique is what makes their estimator so efficient. We show that Rao Blackwellization can be applied to our estimators as well and prove that it is guaranteed to make them more efficient as long as the results of queries are sufficiently variable.
Experimental results. We evaluated the bias and the efficiency of our estimators as well as the estimators from [2,6] on a local search engine that we built over a corpus of 2.4 million documents. To this end, we used the estimators to estimate two different metrics: corpus size and density of sports pages. The empirical study confirms our analytical findings: in the presence of many overflowing queries, our estimators have essentially no bias, while the estimator of Broder et al. suffers from significant bias. For example, the relative bias of AccEst in the corpus size estimation was 0.01%, while the relative bias of the estimator of Broder et al. was 75%. The study also showed that our new estimators are up to 375 times more efficient than the rejection sampling estimator from [2]. Finally, the study demonstrated the effectiveness of Rao-Blackwellization by reducing the query cost of estimators by up to 79%.We used our estimators to measure the absolute sizes of three major search engines. The results of this study gave gross underestimates of the true search engine sizes, largely due to the limited coverage of the pool of queries we used. Even so, we showed that our estimates are up to 74 times higher than the estimates produced by (our implementation of) the Broder et al. estimator.
Other related work. Apart from [4,2,6], several other studies estimated global quality metrics of search engines, like relative corpus size. These studies are based on analyzing anecdotal queries [5], queries collected from user query logs [17,10], or queries selected randomly from a pool a la Bharat and Broder [12,8]. Using capture-recapture techniques (cf. [19]) some of these studies infer measurements of the whole web. Due to the bias in the samples, though, these estimates lack any statistical guarantees.A different approach for evaluating search quality is by sampling pages from the whole web [18,14,15,1,23]. Sampling from the whole web, however, is a more difficult problem, and therefore all the known algorithms suffer from severe bias.
2 Preliminaries
In this section we introduce notations and definitions used throughout the paper.
Search engines. Fix a search engineThe cardinality of a query ![]() , denoted
, denoted
![]() , is the total number of matches it
has. We say that
, is the total number of matches it
has. We say that ![]() overflows, if
overflows, if
![]() , and that it
underflows, if
, and that it
underflows, if
![]() .
.
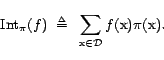
Here,
![]() induces a
corresponding probability distribution on
induces a
corresponding probability distribution on ![]() :
:
![]() , where
, where
![]() is the
normalization constant of
is the
normalization constant of ![]() . We say that two different measures are the same up
to normalization, if they induce the same probability
distribution, but have different normalization constants.
. We say that two different measures are the same up
to normalization, if they induce the same probability
distribution, but have different normalization constants.
When the target measure is a distribution, we call the
integral
![]() an
average metric. Otherwise, it is a sum metric.
For example, corpus size is a sum metric, as the corresponding
target measure is the uniform 1-measure (
an
average metric. Otherwise, it is a sum metric.
For example, corpus size is a sum metric, as the corresponding
target measure is the uniform 1-measure (
![]() for all
for all
![]() ),
while the density of spam pages in the corpus is an average
metric, because its corresponding measure is the uniform
distribution on
),
while the density of spam pages in the corpus is an average
metric, because its corresponding measure is the uniform
distribution on ![]() (
(
![]() for all
for all ![]() ).
).
Everything we do in this paper can be generalized to deal with
vector-valued functions
![]() . Yet, for simplicity of
exposition, we focus on scalar functions.
. Yet, for simplicity of
exposition, we focus on scalar functions.
The quality of an estimator is measured in terms of two
parameters: bias and variance. The
bias of ![]() is the difference
is the difference
![]() .
. ![]() is called
unbiased, if
is called
unbiased, if
![]() . The
variance of
. The
variance of ![]() is
is
![]() . The estimator's bias and variance can be used (via Chebyshev's
inequality) to determine estimation confidence intervals, i.e.,
parameters
. The estimator's bias and variance can be used (via Chebyshev's
inequality) to determine estimation confidence intervals, i.e.,
parameters ![]() and
and
![]() for
which
for
which
![]() .
.
The three expensive resources used by search engine estimators
are: (1) queries submitted to the search engine; (2) web pages
fetched; (3) calculations of the function ![]() . The expected query cost of an estimator
. The expected query cost of an estimator
![]() , denoted
, denoted
![]() , is the expected number of
queries
, is the expected number of
queries ![]() submits to
the search engine. Expected query cost cannot be used to compare
the efficiency of different estimators, as they may have
different variances. The amortized query cost, defined
as
submits to
the search engine. Expected query cost cannot be used to compare
the efficiency of different estimators, as they may have
different variances. The amortized query cost, defined
as
![]() ,
is a more robust measure of efficiency. Expected and amortized
fetch/function costs are defined similarly.
,
is a more robust measure of efficiency. Expected and amortized
fetch/function costs are defined similarly.
The degree of
In practice, however,
![]() may contain queries
that do not belong to
may contain queries
that do not belong to
![]() , and, conversely,
, and, conversely,
![]() may contain queries
that do not belong to
may contain queries
that do not belong to
![]() . We would like to
somehow bridge the gap between the two. Dealing with queries in
. We would like to
somehow bridge the gap between the two. Dealing with queries in
![]() is relatively easy. We call a query
is relatively easy. We call a query ![]() valid for
valid for ![]() , if
, if ![]() belongs to the result set of
belongs to the result set of ![]() and we could have anticipated that by inspecting
the content of
and we could have anticipated that by inspecting
the content of ![]() . That is,
. That is,
![]() . The set of valid results for a query
. The set of valid results for a query ![]() is defined as
follows:
is defined as
follows:
![]() Our algorithms will use only the valid results of queries,
rather than all the results. Therefore, for each document
Our algorithms will use only the valid results of queries,
rather than all the results. Therefore, for each document
![]() , the set of
valid queries for
, the set of
valid queries for ![]() is:
is:
![]() The valid degree of
The valid degree of ![]() , denoted
, denoted
![]() , is
, is
![]() . By using
only valid results, we are guaranteed that
. By using
only valid results, we are guaranteed that
![]() , contributing to shrinking the difference between the two.
, contributing to shrinking the difference between the two.
Addressing queries in
![]() is a more serious problem, because figuring out which of the
queries in
is a more serious problem, because figuring out which of the
queries in
![]() do not belong to
do not belong to
![]() requires submitting
all these queries to the search engine--a prohibitively expensive
task. We call the ratio
requires submitting
all these queries to the search engine--a prohibitively expensive
task. We call the ratio
![]() the validity density of
the validity density of ![]() and denote it by
and denote it by
![]() . From the above,
. From the above,
![]() for all
for all
![]() . The closer
. The closer
![]() is to 1, the better
is our approximation of
is to 1, the better
is our approximation of
![]() .
.
Usage of the ![]() available results of overflowing queries in our estimations is a
potential source of bias, since such queries may favor documents
with high static rank. In order to eliminate any bias towards
such documents, our algorithms simply ignore overflowing queries.
Technically, we do this by defining all the results of
overflowing queries to be ``invalid''. Therefore, if
available results of overflowing queries in our estimations is a
potential source of bias, since such queries may favor documents
with high static rank. In order to eliminate any bias towards
such documents, our algorithms simply ignore overflowing queries.
Technically, we do this by defining all the results of
overflowing queries to be ``invalid''. Therefore, if ![]() overflows,
overflows,
![]() . This in particular
means that
. This in particular
means that
![]() cannot contain any
overflowing query.
cannot contain any
overflowing query.
We say that the pool ![]() covers a document
covers a document ![]() , if there is at least one query
, if there is at least one query
![]() which is valid for
which is valid for ![]() .
That is,
.
That is,
![]() . Note
that documents that do not contain any of the terms/phrases in
. Note
that documents that do not contain any of the terms/phrases in
![]() or that match
only overflowing queries in
or that match
only overflowing queries in ![]() are not covered by
are not covered by ![]() .
.
3 Importance sampling
In this section we present a basic importance sampling search engine estimator. It will be used as a basis for the more advanced estimators presented in subsequent sections.
Setup. Like the pool-based estimators in [4,2,6], our estimator assumes knowledge of an explicit query poolNo matter how large ![]() is, in practice, there will always be documents in
is, in practice, there will always be documents in ![]() that
that ![]() does not cover.
Since our estimator uses only queries from
does not cover.
Since our estimator uses only queries from ![]() , it can never
reach such documents. This means that our estimator can estimate
integrals only over the set of documents that are covered by
, it can never
reach such documents. This means that our estimator can estimate
integrals only over the set of documents that are covered by
![]() and not over
the entire corpus
and not over
the entire corpus ![]() .
So regardless of the statistical bias of the estimator, there
will be an additional ``built-in'' bias that depends on the
coverage of the chosen query pool. To simplify our discussion,
from now on, we suppress this coverage-induced bias and use
.
So regardless of the statistical bias of the estimator, there
will be an additional ``built-in'' bias that depends on the
coverage of the chosen query pool. To simplify our discussion,
from now on, we suppress this coverage-induced bias and use
![]() to denote only
the documents that are covered by
to denote only
the documents that are covered by ![]() .
.
In our setting, however, this simple estimator is impractical,
for the following reasons: (1) sampling from the distribution
![]() may be hard or
costly (e.g., when
may be hard or
costly (e.g., when ![]() is a
uniform measure on
is a
uniform measure on ![]() );
(2) computation of the normalization constant
);
(2) computation of the normalization constant ![]() may be costly
(e.g., in corpus size estimation,
may be costly
(e.g., in corpus size estimation,
![]() , which is exactly the quantity
we need to estimate); (3) the random variable
, which is exactly the quantity
we need to estimate); (3) the random variable ![]() may have high
variance. Importance sampling [21,16,20] can be used in
these circumstances to obtain a more efficient estimator.
may have high
variance. Importance sampling [21,16,20] can be used in
these circumstances to obtain a more efficient estimator.
The basic idea of importance sampling is the following.
Instead of sampling a document ![]() from
from ![]() , the
estimator samples a document
, the
estimator samples a document ![]() from a different trial distribution
from a different trial distribution
![]() on
on ![]() .
. ![]() can be any
distribution, as long as
can be any
distribution, as long as
![]() (here,
(here,
![]() is the support of
is the support of ![]() ;
;
![]() is
defined similarly). In particular, we can choose it to be a
distribution that is easy to sample from. The importance sampling
estimator is then defined as follows:
is
defined similarly). In particular, we can choose it to be a
distribution that is easy to sample from. The importance sampling
estimator is then defined as follows:
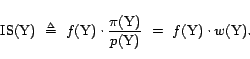
The correction term
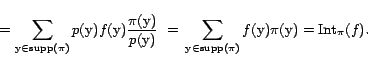
Implementation of an importance sampling estimator requires: (1) ability to sample efficiently from the trial distribution
In this paper we propose a different sample space. Rather than
sampling queries and then documents in two separate steps, we
sample them together. The sample space is then
![]() . Each sample is a
query-document pair
. Each sample is a
query-document pair
![]() . We
extend the target measure
. We
extend the target measure ![]() on
on ![]() into a
target measure
into a
target measure ![]() on
on
![]() and the function
and the function
![]() on
on ![]() into a function
into a function
![]() on
on ![]() . The extension is
done in such a way that
. The extension is
done in such a way that
![]() equals
equals
![]() . We
thus reduce the problem of estimating
. We
thus reduce the problem of estimating
![]() to
the problem of estimating
to
the problem of estimating
![]() .
For the latter, we can apply importance sampling directly on the
two-dimensional sample space
.
For the latter, we can apply importance sampling directly on the
two-dimensional sample space ![]() , without having to resort to rejection sampling.
, without having to resort to rejection sampling.
Let
![]() . We extend
. We extend ![]() into a measure on
into a measure on
![]() as follows:
as follows:
![]() where
where ![]() is an indicator
function:
is an indicator
function:
![]() if the condition is true, and
if the condition is true, and ![]() otherwise. The connection between
otherwise. The connection between ![]() and
and ![]() is given by
the following proposition:
is given by
the following proposition:
Similarly, we extend the function ![]() on
on ![]() into a
function
into a
function ![]() on
on ![]() as follows:
as follows:
![]() It
is easy to see that
It
is easy to see that
![]() . Our
estimator therefore estimates the integral
. Our
estimator therefore estimates the integral
![]() .
.
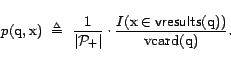
Here,

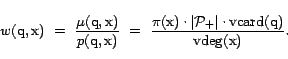
Thus, the importance sampling estimator for
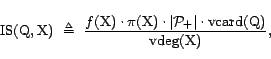
where
The estimator of Broder et al. [6] resembles the above
importance sampling estimator for the special case of corpus size
estimation. As they could not compute the exact importance
weights, they used approximate importance weights, by
substituting
![]() for
for
![]() . It is not clear, however, what is
the effect of the approximate importance weights on the bias of
the estimator. Also, it is unknown how to extend the estimator to
work for average metrics. We address these issues in the next
section.
. It is not clear, however, what is
the effect of the approximate importance weights on the bias of
the estimator. Also, it is unknown how to extend the estimator to
work for average metrics. We address these issues in the next
section.
4 Approximate importance
sampling
Suppose we come up with an approximate weight
function
![]() ,
which is ``similar'', but not identical, to
,
which is ``similar'', but not identical, to
![]() (we
will discuss possible alternatives for
(we
will discuss possible alternatives for
![]() in
the next section). What is the effect of using
in
the next section). What is the effect of using
![]() rather than
rather than
![]() in
importance sampling? In the following we analyze the quality and
performance of this ``approximate importance sampling''
procedure.
in
importance sampling? In the following we analyze the quality and
performance of this ``approximate importance sampling''
procedure.
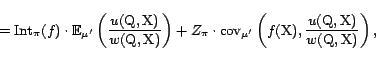
For lack of space, the proof of this lemma, as the proofs of all the other results in this paper, are postponed to the full version of the paper [3].
It follows from the lemma that there are two sources of bias
in this estimator: (1) multiplicative bias, depending on the
expectation of ![]() under
under
![]() ; and (2) additive
bias, depending on the correlation between
; and (2) additive
bias, depending on the correlation between ![]() and
and ![]() and on the
normalization constant
and on the
normalization constant ![]() .
Note that the multiplicative factor, even if small, may have a
significant effect on the estimator's bias, and thus must be
eliminated. The additive bias is typically less significant, as
in many practical situations
.
Note that the multiplicative factor, even if small, may have a
significant effect on the estimator's bias, and thus must be
eliminated. The additive bias is typically less significant, as
in many practical situations ![]() and
and ![]() are uncorrelated
(e.g., when
are uncorrelated
(e.g., when ![]() is a constant
function as is the case with corpus size estimation).
is a constant
function as is the case with corpus size estimation).
For a query-document pair
![]() , the
ratio
, the
ratio
![]() is called the
weight skew at
is called the
weight skew at
![]() .
The multiplicative bias factor is the expected weight skew under
the target distribution
.
The multiplicative bias factor is the expected weight skew under
the target distribution ![]() . In order to eliminate this bias, we need to somehow
estimate the expected weight skew. For now, let us assume we have
some unbiased estimator
. In order to eliminate this bias, we need to somehow
estimate the expected weight skew. For now, let us assume we have
some unbiased estimator
![]() for
for
![]() (
(
![]() may
depend on the same sample
may
depend on the same sample
![]() used
by the importance sampling estimator). It follows from Lemma
4.1 that:
used
by the importance sampling estimator). It follows from Lemma
4.1 that:
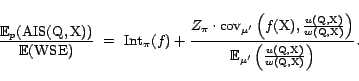
Thus, the ratio of the expectations of the two estimators,
To solve this problem, we resort to a well-known trick from statistics: if we replace the numerator and the denominator by averages of multiple independent instances of the numerator estimator and of the denominator estimator, the difference between the expected ratio and the ratio of expectations can be diminished to 0. This idea is formalized by the following theorem:
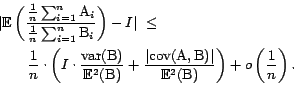
We can therefore define the approximate ratio importance
sampling estimator for
![]() as
follows:
as
follows:
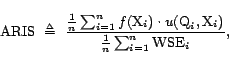
where
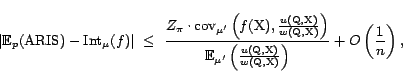
We conclude from the lemma that if we use sufficiently many
samples, then we are likely to get an estimate of
![]() ,
which has only additive bias that depends on the correlation
between
,
which has only additive bias that depends on the correlation
between ![]() and
and ![]() .
.
5 Two estimators
In this section we describe two variants of the approximate
ratio importance sampling estimator (
![]() )
discussed above. The two estimators, the Accurate Estimator
(AccEst) and the Efficient Estimator (EffEst), offer different
tradeoffs between accuracy and efficiency. The former has lower
bias, while the latter is more efficient.
)
discussed above. The two estimators, the Accurate Estimator
(AccEst) and the Efficient Estimator (EffEst), offer different
tradeoffs between accuracy and efficiency. The former has lower
bias, while the latter is more efficient.
The estimators differ in the choice of the approximate
importance weight function
![]() and
in the expected weight skew estimator
and
in the expected weight skew estimator
![]() . Before
we show how
. Before
we show how ![]() and
and
![]() are
defined in each of the estimators, let us rewrite the importance
weights:
are
defined in each of the estimators, let us rewrite the importance
weights:
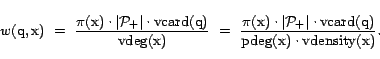
Of the different terms that constitute the weight, the three we may not know a priori are
1 The Accurate Estimator
The Accurate Estimator (AccEst) uses approximate weights
![]() that are equal to the
exact weights
that are equal to the
exact weights
![]() , up
to a constant factor. It follows that
, up
to a constant factor. It follows that
![]() is
constant, and hence the correlation between
is
constant, and hence the correlation between ![]() and
and
![]() is 0.
Using Lemma 4.3, the bias of AccEst is
then only
is 0.
Using Lemma 4.3, the bias of AccEst is
then only ![]() .
.
How do we come up with approximate weights that equal the
exact weights up to a constant factor? Well, we are unable to
efficiently do this with deterministic approximate weights, but
rather with probabilistic ones. That is, AccEst uses a
probabilistic weight function
![]() , for which
, for which
![]() . As our analysis for approximate importance sampling easily
carries over to probabilistic weights as well, we can still apply
Lemma 4.3 and obtain the desired bound
on the bias of AccEst.
. As our analysis for approximate importance sampling easily
carries over to probabilistic weights as well, we can still apply
Lemma 4.3 and obtain the desired bound
on the bias of AccEst.
The approximate weights are defined as follows:
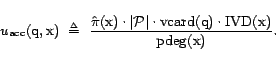
That is,
Figure 2 shows a procedure for
estimating
![]() for a given document
for a given document
![]() , using a limited
number of queries. The procedure repeatedly samples queries
uniformly at random from the set of predicted queries
, using a limited
number of queries. The procedure repeatedly samples queries
uniformly at random from the set of predicted queries
![]() . It submits each query to the
search engine and checks whether they are valid for
. It submits each query to the
search engine and checks whether they are valid for ![]() . The procedure
stops when reaching the first valid query and returns the number
of queries sampled so far. As this number is geometrically
distributed with
. The procedure
stops when reaching the first valid query and returns the number
of queries sampled so far. As this number is geometrically
distributed with
![]() as the success parameter, the
expectation of this estimator is exactly
as the success parameter, the
expectation of this estimator is exactly
![]() . Note that the procedure is
always guaranteed to terminate, because we apply it only on
documents
. Note that the procedure is
always guaranteed to terminate, because we apply it only on
documents ![]() for which
for which
![]() .
.

The expectation of
![]() is analyzed as
follows:
is analyzed as
follows:
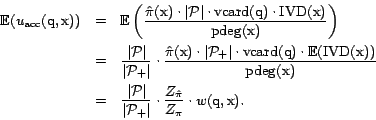
Hence, the expectation of
If we sample a query ![]() uniformly at random from
uniformly at random from ![]() , it has a probability of
, it has a probability of
![]() to have at
least one valid result. Therefore, we can estimate
to have at
least one valid result. Therefore, we can estimate
![]() as
follows: repeatedly sample queries uniformly at random from
as
follows: repeatedly sample queries uniformly at random from
![]() and submit them
to the search engine; stop when reaching the first query that has
at least one valid result; the number of queries submitted is an
unbiased estimator of
and submit them
to the search engine; stop when reaching the first query that has
at least one valid result; the number of queries submitted is an
unbiased estimator of
![]() .
.
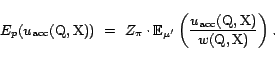
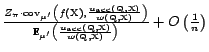 . Recall that the covariance term is 0, and thus the bias is only
. Recall that the covariance term is 0, and thus the bias is only
The cost of the computing
![]() is dominated by the cost
of computing the inverse validity density. This computation
requires
is dominated by the cost
of computing the inverse validity density. This computation
requires
![]() queries to the search
engine in expectation. Complete analysis of the efficiency of the
estimator is postponed to the full version of the paper.
queries to the search
engine in expectation. Complete analysis of the efficiency of the
estimator is postponed to the full version of the paper.
2 The Efficient Estimator
The Efficient Estimator (EffEst) uses deterministic approximate weights, which require no queries to the search engine to compute, similarly to the estimators of [2,6]: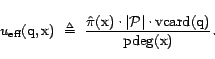
That is,
The estimator for the expected weight skew is again different
between the case
![]() is
a sum metric and the case
is
a sum metric and the case
![]() is
an average metric.
is
an average metric.
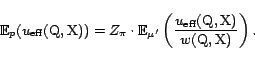
In our case
We observe that
![]() , where
, where ![]() is the
constant 1 function. So by applying the Accurate Estimator with
is the
constant 1 function. So by applying the Accurate Estimator with
![]() , we
can obtain an unbiased estimator of
, we
can obtain an unbiased estimator of ![]() . We thus have:
. We thus have:
![]() . So, using again Theorem 4.2, we
can get a nearly unbiased estimator of the expected weight skew
by averaging over multiple instances of
. So, using again Theorem 4.2, we
can get a nearly unbiased estimator of the expected weight skew
by averaging over multiple instances of
![]() and AccEst:
and AccEst:
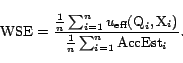
Here,
At this point the reader may be wonder why the Efficient
Estimator is more efficient than the Accurate Estimator. After
all, the Efficient Estimator calls the Accurate Estimator! The
rationale behind this is the following. Indeed, if we need to
estimate only a single integral
![]() ,
then the Efficient Estimator is less efficient than the Accurate
Estimator. However, in practice, we usually need to compute
multiple integrals
,
then the Efficient Estimator is less efficient than the Accurate
Estimator. However, in practice, we usually need to compute
multiple integrals
![]() w.r.t. the same target measure
w.r.t. the same target measure ![]() . Note that the constant
. Note that the constant ![]() , for whose estimation we used the Accurate Estimator,
depends only on
, for whose estimation we used the Accurate Estimator,
depends only on ![]() and is
independent of the target function
and is
independent of the target function ![]() . Therefore, we can reuse the estimation of
. Therefore, we can reuse the estimation of
![]() in the estimations
of
in the estimations
of
![]() . This
implies that the amortized cost of the Efficient
Estimator is lower than that of the Accurate
Estimator.
. This
implies that the amortized cost of the Efficient
Estimator is lower than that of the Accurate
Estimator.
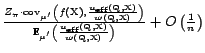 . By the characterization of the weight skew using the validity
density (Proposition 5.2) and
recalling that
. By the characterization of the weight skew using the validity
density (Proposition 5.2) and
recalling that 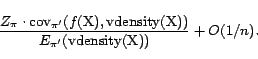
That is, as long as the target function is not correlated with the validity density of documents, the bias is low.
The Efficient Estimator is indeed efficient, because each approximate weight computation requires only fetching a single page from the web and no queries to the search engine. Complete analysis of the efficiency of the estimator is postponed to the full version of this paper.
6 Rao-Blackwellization
There is some inherent inefficiency in the importance sampling estimators: although each random query they submit to the search engine returns many results, they use at most a single result per query. All other results are discarded. The corpus size estimator of Broder et al. [6] uses all query results, and not just one. We observe that what they did is an instance of the well-known Rao-Blackwellization technique for reducing estimation variance. We next show how to apply Rao-Blackwellization on our importance sampling estimators in a similar fashion.
Recall that the basic approximate importance sampling
estimator is
![]() , where
, where
![]() is a
sample from the trial distribution
is a
sample from the trial distribution ![]() and
and
![]() is
an approximate weight. Suppose now that instead of using only
this single document in our basic estimator, we use all the query
results:
is
an approximate weight. Suppose now that instead of using only
this single document in our basic estimator, we use all the query
results:
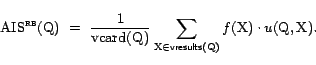
Each instance of
By the above theorem, the expected reduction in variance is
![]() where
where ![]() is a uniformly
chosen query from
is a uniformly
chosen query from ![]() and
and ![]() is a uniformly chosen document from
is a uniformly chosen document from ![]() . That is, the more variable are the results of
queries w.r.t. the target function
. That is, the more variable are the results of
queries w.r.t. the target function ![]() , the higher are the chances that Rao-Blackwellization will
help. In our empirical study we show that in practice
Rao-Blackwellization can make a dramatic effect. See Section
7.
, the higher are the chances that Rao-Blackwellization will
help. In our empirical study we show that in practice
Rao-Blackwellization can make a dramatic effect. See Section
7.
The variance reduction achieved by Rao-Blackwellization can lead to lower costs, as fewer instances of the estimator are needed in order to obtain a desired accuracy guarantee. On the other hand, each instance of the estimator requires many more weight and function calculations (as many as the number of results of the sampled query), and if these are very costly (as is the case with the Accurate Estimator), then the increase in cost per instance may outweigh the reduction in the number of instances, eventually leading to higher amortized costs. We conclude that Rao-Blackwellization should be used judiciously.
7 Experimental results
We conducted two sets of experiments. In the first set we performed comparative evaluation of the bias and amortized cost of our new estimators, of the rejection sampling estimator from our previous paper [2], and of the Broder et al. estimator [6]. To this end, we ran all these estimators on a local search engine that we built over 2.4 million English documents fetched from ODP [9]. As we have ground truth for this search engine, we could compare the measurements produced by the estimators against the real values.
The second set of experiments was conducted over three major real search engines. We used the Accurate Estimator to estimate the corpus size of each the search engines, with and without duplicate elimination. (More accurately, we estimated sizes of large subsets of the search engine corpora.)
Experimental setup. We used the same ODP search engine as in our previous paper [2]. The corpus of this search engine consists only of text, HTML, and pdf English-language documents from the ODP hierarchy. Each document was given a serial id and indexed by single terms and phrases. Only the first 10,000 terms in each document were considered. Exact phrases were not allowed to cross boundaries, such as paragraph boundaries. We used static ranking by serial id to rank query results.In order to construct a query pool for the evaluation experiments, we split the ODP data set into two parts: a training set, consisting of every fifth page (when ordered by id), and a test set, consisting of the rest of the pages. We used the training set to create a pool of phrases of length 4. The measurements were done only on the test set.
The experiments on real search engines were conducted in February 2007. The pool used by our estimators was a pool of 1.75 billion phrases of lengths 3-5 extracted from the ODP data set (the entire data set, not just the test set).
Evaluation experiments. We compared the following 6 estimator configurations: (1) AccEst, without Rao Blackwellization; (2) AccEst, with Rao Blackwellization; (3) EffEst, without Rao Blackwellization; (4) EffEst, with Rao Blackwellization; (5) the Broder et al. estimator; (6) the rejection sampling estimator from our previous paper.We used the estimators to measure two metrics: (1) corpus size (i.e., the size of the test set); (2) density of pages in the test set about sports. (We used a simple keyword based classifier to determine whether a page is about sports or not.) Note that the first metric is a sum metric, while the second is an average metric. We did not use the rejection sampling estimator for estimating corpus size, as it can handle only average metrics. We did not use the Broder et al. estimator for estimating the density of sports pages, because it can handle only sum metrics.
In order to have a common baseline, we allowed each estimator to use exactly 1 million queries. Each estimator produced a different number of samples from these queries, depending on its amortized query cost.
We ran each experiment four times, with different values of
the result set size limit ![]() (
(
![]() ). This
was done in order to track the dependence of the estimators' bias
and cost on the density of overflowing queries (the lower
). This
was done in order to track the dependence of the estimators' bias
and cost on the density of overflowing queries (the lower
![]() , the higher is the
density).
, the higher is the
density).
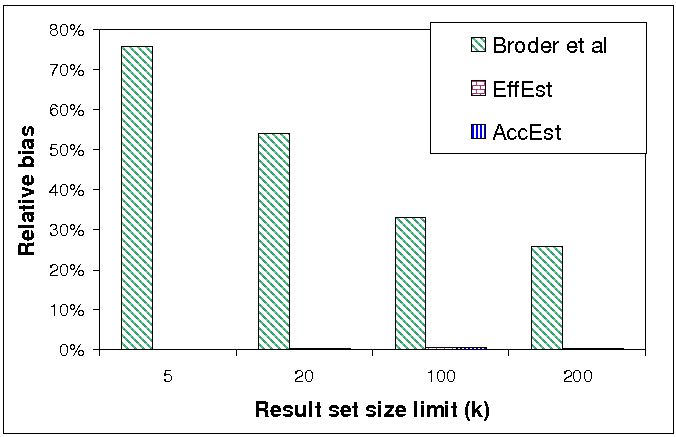
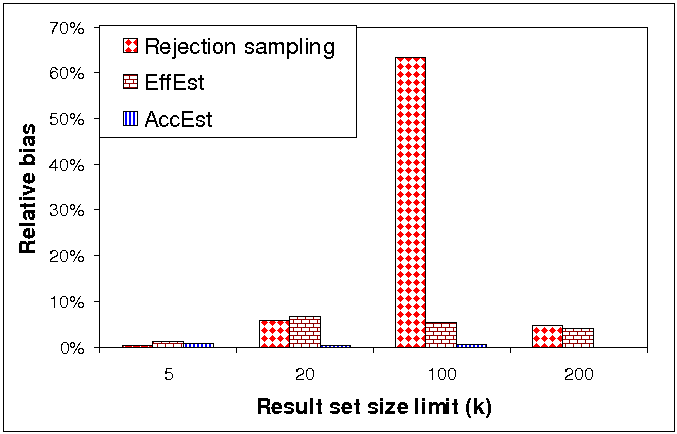
Figure 3(a) compares the relative bias (bias divided by the estimated quantity) of our two estimators and the estimator of Broder et al. when measuring corpus size. Figure 3(b) compares the relative bias of our two estimators and the rejection sampling estimator when measuring density of sports pages. The results for the Rao-Blackwellized versions of these estimators are suppressed, since Rao-Blackwellization has no effect on bias.
The results for the corpus size clearly show that our
estimators have no bias at all, while the estimator of Broder
et al suffers from significant bias, which grows with
the density of overflowing queries in the pool. For example, for
![]() , the relative bias
of the Broder et al. estimator was about 75%, while the
relative bias of our estimators was 0.01%. Note that since the
target function is constant in this case, then its value has no
correlation with the weight skew, which explains why also EffEst
has no bias.
, the relative bias
of the Broder et al. estimator was about 75%, while the
relative bias of our estimators was 0.01%. Note that since the
target function is constant in this case, then its value has no
correlation with the weight skew, which explains why also EffEst
has no bias.
The results for the density of sports pages show that AccEst is unbiased, as expected. EffEst has small bias, which emanates from a weak correlation between the function value and the validity density. The rejection sampling method has a large observed bias, primarily because it produced a small number of samples and thus its variance is still high.
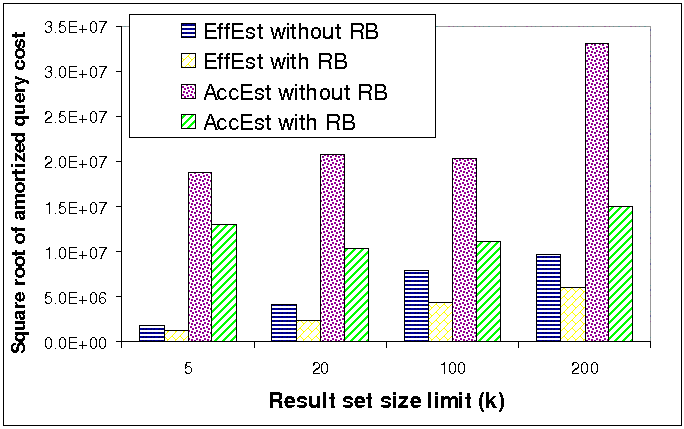
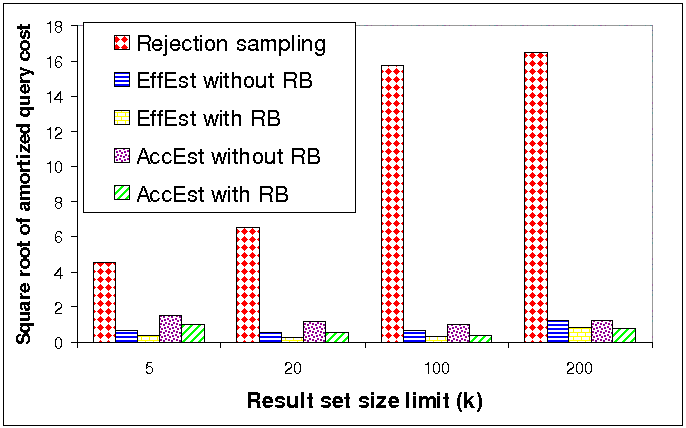
Figures 4(a) and 4(b) compare the amortized costs of
the regular and the Rao-Blackwellized versions of our two
estimators and of the rejection sampling estimator. We used a
square root scale in order to fit all the bars in a single graph.
The results clearly indicate that Rao-Blackwellization is
effective in reducing estimation variance (and therefore also
amortized costs) in both metrics and both estimators. For
example, in corpus size estimation, when ![]() ,
Rao-Blackwellization reduced the amortized query cost of AccEst
by 79% and the query cost of EffEst by 60%. Furthermore, the
amortized cost of the rejection sampling estimator is
tremendously higher than the amortized cost of our new estimators
(even the non-Rao-Blackwellized ones). For example, when
,
Rao-Blackwellization reduced the amortized query cost of AccEst
by 79% and the query cost of EffEst by 60%. Furthermore, the
amortized cost of the rejection sampling estimator is
tremendously higher than the amortized cost of our new estimators
(even the non-Rao-Blackwellized ones). For example, when
![]() ,
Rao-Blackwellized EffEst was 375 times more efficient than
rejection sampling!
,
Rao-Blackwellized EffEst was 375 times more efficient than
rejection sampling!
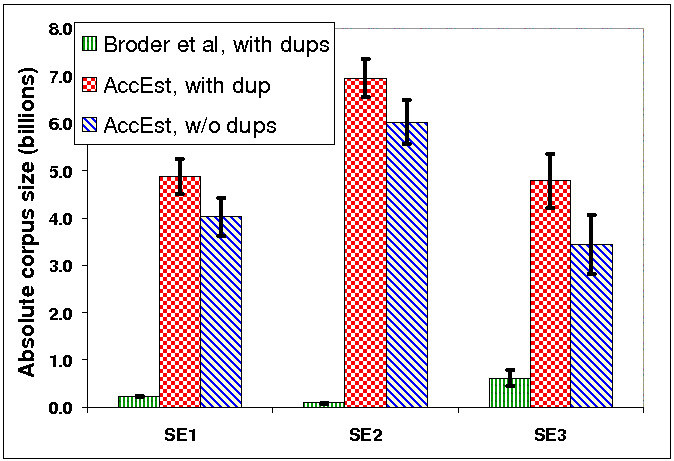
It can be seen that the estimations we got are far below the reported sizes of search engines. The main reason for this is that our estimators effectively measure the sizes of only subsets of the corpora--the indexed pages that match at least one phrase from the pool. As our pool consists of English-only phrases, pages that are not in English, not in HTML, pdf, or text format, or pages that are poor in text, are excluded from the measurement. A second reason is that search engines may choose sometimes not to serve certain pages, even though these pages exist in their index and match the query, e.g., because these pages are spam or duplicates.
Another observation we can make from the results is that overflowing queries really hurt the Broder et al. estimator also on live search engines. We note that like Broder et al, we filtered out from the query pool all phrases that occurred frequently (at least 10 times) in the ODP corpus. Even after this filtering, 3% of the queries overflowed on the first search engine, 10% on the second, and 7% on the third. The overflowing queries probably incurred high bias that made the estimates produced by the Broder et al. estimator to be much lower than ours.
Finally, the experiments reveal search engines deal differently with duplicates. In one of the search engines, the corpus size, after removing duplicates, shrunk in 28%, while in the other two it shrunk in 14% and 17%, respectively.
8 Conclusions
In this paper we presented two new estimators
for search engine quality metrics that can be expressed as
discrete integrals. Our estimators are able to overcome the
``degree mismatch'' problem and thereby be accurate and efficient
at the same time. We show both analytically and empirically that
our estimators beat recently proposed estimators [2,6].
In designing our estimators we employ a combination of statistical tools, like importance sampling and Rao Blackwellization. By carefully analyzing the effect of approximate weights on the bias of importance sampling, we were able to design procedures to mitigate the bias. This bias-elimination technique for approximate importance sampling may be applicable in other scenarios as well.
REFERENCES
[1] Z. Bar-Yossef, A. Berg, S. Chien, J. Fakcharoenphol, and D. Weitz. Approximating aggregate queries about Web pages via random walks. In Proc. 26th VLDB, pages 535-544, 2000.
[2] Z. Bar-Yossef and M. Gurevich. Random sampling from a search engine's index. In Proc. 15th WWW, pages 367-376, 2006.
[3] Z. Bar-Yossef and M. Gurevich. Efficient search engine measurements, 2007. Full version available at http://www.ee.technion.ac.il/people/zivby.
[4] K. Bharat and A. Broder. A technique for measuring the relative size and overlap of public Web search engines. In Proc. 7th WWW, pages 379-388, 1998.
[5] E. T. Bradlow and D. C. Schmittlein. The little engines that could: Modeling the performance of World Wide Web search engines. Marketing Science, 19:43-62, 2000.
[6] A. Broder, M. Fontoura, V. Josifovski, R. Kumar, R. Motwani, S. Nabar, R. Panigrahy, A. Tomkins, and Y. Xu. Estimating corpus size via queries. Proc. 15th CIKM, 2006.
[7] G. Casella and C. P. Robert. Rao-Blackwellisation of sampling schemes. Biometrika, 83(1):81-94, 1996.
[8] M. Cheney and M. Perry. A comparison of the size of the Yahoo! and Google indices. Available at http://vburton.ncsa.uiuc.edu/indexsize.html, 2005.
[9] dmoz. The open directory project. http://dmoz.org.
[10] A. Dobra and S. E. Fienberg. How large is the World Wide Web? Web Dynamics, pages 23-44, 2004.
[11] O. Goldreich. A sample of samplers - a computational perspective on sampling (survey). ECCC, 4(20), 1997.
[12] A. Gulli and A. Signorini. The indexable Web is more than 11.5 billion pages. In Proc. 14th WWW, pages 902-903, 2005.
[13] W. K. Hastings. Monte Carlo sampling methods using Markov chains and their applications. Biometrika, 57(1):97-109, 1970.
[14] M. R. Henzinger, A. Heydon, M. Mitzenmacher, and M. Najork. Measuring index quality using random walks on the Web. In Proc. 8th WWW, pages 213-225, 1999.
[15] M. R. Henzinger, A. Heydon, M. Mitzenmacher, and M. Najork. On near-uniform URL sampling. In Proc. 9th WWW, pages 295-308, 2000.
[16] T. C. Hesterberg. Advances in Importance Sampling. PhD thesis, Stanford University, 1988.
[17] S. Lawrence and C. L. Giles. Searching the World Wide Web. Science, 5360(280):98, 1998.
[18] S. Lawrence and C. L. Giles. Accessibility of information on the Web. Nature, 400:107-109, 1999.
[19] S.-M. Lee and A. Chao. Estimating population size via sample coverage for closed capture-recapture models. Biometrics, 50(1):88-97, 1994.
[20] J. S. Liu. Monte Carlo Strategies in Scientific Computing. Springer, 2001.
[21] A. W. Marshal. The use of multi-stage sampling schemes in Monte Carlo computations. In Symposium on Monte Carlo Methods, pages 123-140, 1956.
[22] N. Metropolis, A. Rosenbluth, M. Rosenbluth, A. Teller, and E. Teller. Equations of state calculations by fast computing machines. J. of Chemical Physics, 21:1087-1091, 1953.
[23] P. Rusmevichientong, D. Pennock, S. Lawrence, and C. L. Giles. Methods for sampling pages uniformly from the World Wide Web. In Proc. AAAI Symp. on Using Uncertainty within Computation, 2001.
[24] J. von Neumann. Various techniques used in connection with random digits. In John von Neumann, Collected Works, volume V. Oxford, 1963.
Footnotes
- 1
- More efficient aggregation techniques, like the median of averages (cf. [11,6]), exist. For simplicity of exposition, we will focus mainly on averaging in this paper.